[vc_row][vc_column][vc_column_text]Real-life datasets often contain missing values. Majority of the machine learning algorithm can not be allowed missing values. So, we need to handle missing values. To handle missing values is itself a very tedious task.
Real-life data contain missing values by various reason such as human have skipped to enter values intentionally or unintentionally, some typo error during data collection, data corruption and many more.
There are multiple ways to handle missing values. In this tutorial, I have explained various techniques to handle missing values with example in Python.
Remove features with Missing values
Just remove the feature which contains Missing Values. But, this is not an ideal way to handle Missing Values in machine learning. We may lose important information by removing the entire feature. We can use this approach if the feature has more than 97% missing values.
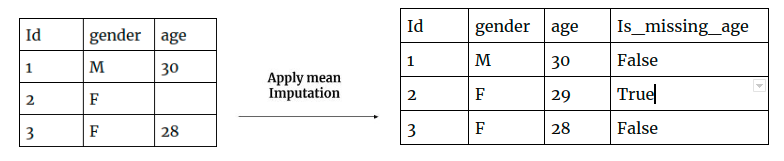
Impute Missing Values
Just replace missing values by another value. There are various option to replace Missing Values.
- Replace Missing Values by Constant Value, distinct from all other values like 0 or -999
- Replace Missing Values by mean, mode or median value of the feature.
- Replace by randomly selected value from feature.
Pandas Python package provides fillna() built-in function to fill missing values by a specific value.
Scikit-learn Python package also provides Imputation class SimpleImputer that can be used to replace missing values. This class provide an imputation strategy parameter which has default mean value for Imputation.
Extension to Imputation
Imputation is the best way to handle missing values instead of dropping the feature with missing values. However, the Imputed values are not perfect value, It may be somewhat above or below to actual values. In that case, your model gives better accuracy by considering which values were originally missing.
Example:
The following ipython notebook describes these approaches to handle missing values.
Here, I have used Kaggle’s competition dataset for illustration.
Link: https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview
My Github Link: https://github.com/bhavikapanara/Data-Cleaning
[/vc_column_text][/vc_column][/vc_row]