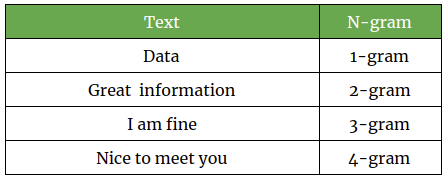
An N-gram is a contiguous sequence of n items from a given sample of text or speech. In Natural Language Processing, the concept of N-gram is widely used for text analysis. An N-gram of size 1 is referred to as a “unigram“, size 2 is a “bigram”, size 3 is a “trigram”.
Example:
text = “The Margherita pizza has very good taste.”
If we consider N=2, then N-gram would be:
- The Margherita
- Margherita pizza
- pizza has
- has very
- very good
- good taste
. . .
Why N-gram?
An N-gram plays important role in text analysis in Machine Learning. Sometimes a single word alone isn’t sufficient to observe the context of a text. Let’s see how N-gram will useful for text analysis using an example.
For example, we need to predict the sentiment of the text such as positive or negative.
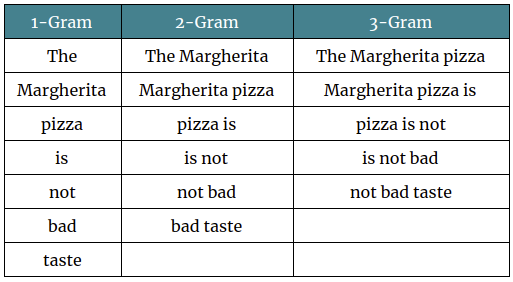
text = “The Margherita pizza is not bad taste”
If we consider unigram or a single word for text analysis, the negative word “bad” lead to the wrong prediction of the text. But if we use bigram, the bigram word “not bad” helps to predict the text as a positive sentiment.
. . .
No. of N-gram in a sentence:
No. of N-gram = X - (N - 1)
Where,
X is the total number of words in a sentence.
K is an N-gram value
. . .