Feature preprocessing is one of the important parts of Machine Learning. Feature preprocessing of numeric data is mainly focused on the scaling (standardized) of the data. Feature Scaling is the process of standardized features to the same scales. Some models are influenced by feature Scaling, while others are not. Non-tree based models are easily influenced by feature Scaling. And the Tree-based models are not influenced by feature scaling.
Machine Learning algorithms are generally divided into two parts.
Tree-based model: Tree-based model find the most useful split for each feature. The tree-based model won’t change its behaviour even if we multiply or divide with constant features. Its predictions remain the same. It doesn’t depend on the relative positioning of the features.
- Random Forest
- Decision Tree
- Gradient boosted Trees
Non-tree based model: Non-Tree based model are dependent on the position of the feature.
- Linear Models
- K-nearest neighbour classifier
- Neural Networks
Example: Let’s see the example of binary classification with two features.

Here, the red circle represent class 0 and blue cross represent class 1. And we supposed to predict the class of green object.
If we use k-nearest neighbour classification, the unknown green object goes to class 1, as the distance with class 1 is less than class 0.
But, we multiply the first feature by constant 10, then k-nearest neighbour classifier classifies green object to class 0, as it is a much closer object.

KNN model faces difficulty to predict the class label of different scale features. Linear model and neural network model also suffer from such different scale features. Hence, Feature Scaling is required for non-tree based models. There are many methods exists for feature scaling.
MinMaxScaler:
MinMaxScaler scales values between [0,1]
The Scikit-learn provide the implementation of sklearn.preprocessing.MinMaxScaler.

from sklearn.preprocessing import MinMaxScaler sc = MinMaxScaler() data = sc.fit_transform(data))
StandardScaler:
Scale the data by setting the mean of the data 0 and the standard deviation to 1. StandardScaler first subtracts the mean value from feature and then divided by feature standard deviation. The Scikit-learn provides the implementation of sklearn.preprocessing.StandardScaler.
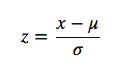
from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit_transform(data))