Stemming and Lemmatization is the method to normalize the text documents. The main goal of the text normalization is to keep the vocabulary small, which help to improve the accuracy of many language modelling tasks.
For example, vocabulary size will be reduced if we transform each word to lowercase. Hence, the difference between How and how is ignored.
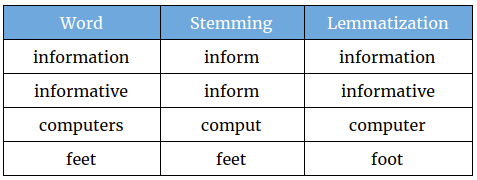
Stemming and Lemmatization help us to normalize text and improve the vocabulary by reducing the inflectional forms. It is the process of converting a word to its base form.
Stemming
Stemming usually refers to a process of chopping off the last few characters. Stemming operates on a single word without knowledge of the context. Stemming is not a well-defined process, it often suffers from incorrect meaning and spelling errors.
Stemmers use language-specific rules, but they require less knowledge than a lemmatizer. There are several Stemming algorithms are exist. All these stemming algorithms have their own behaviour.
NLTK provides various stemmer in different languages such as English, German, French, Finnish, Danish, Dutch, Hungarian, Italian, etc. The nltk.stem package provides the implementation of the stemmer.
Let’s see the behaviour of the below three stemmers:
- Porter Stemmer
- Snowball Stemmer
- Lancaster Stemmer
Example
from nltk.stem.snowball import SnowballStemmer
from nltk.stem import LancasterStemmer
from nltk.stem import PorterStemmer
ss = SnowballStemmer('english')
ps =PorterStemmer()
words= ["wait", "waiting", "waited", "waits"]
for e in words:
ps_stem_Word = ps.stem(e)
ss_stem_Word = ss.stem(e)
print('Word: {} -> PorterStemmer: {} & SnowballStemmer: {} '.format(e,ps_stem_Word,ss_stem_Word))
Output –
Word: wait -> PorterStemmer: wait & SnowballStemmer: wait Word: waiting -> PorterStemmer: wait & SnowballStemmer: wait Word: waited -> PorterStemmer: wait & SnowballStemmer: wait Word: waits -> PorterStemmer: wait & SnowballStemmer: wait
Lemmatization
Lemmatization is closely related to Stemming, but the main difference is that Lemmatization considers the morphological analysis of the words and converts the word with meaningful way.
Lemmatization needs a complete vocabulary and morphological analysis to correctly lemmatize words. Lemmatization is better to use instead of Stemming as at least lemmatization doesn’t vanish the meaning of the word.
NLTK provides WordNet lemmatizer, which only removes affixes if the resulting word is present in its dictionary. Lemmatizer is slower than stemmers, as the lemmatizer need to check the resultant word in the dictionary.
Let’s see the example of WordNet lemmatizer:
Example
from nltk.stem import WordNetLemmatizer
wordnet_lemma = WordNetLemmatizer()
words= ["wait", "waiting", "waited", "waits"]
for e in words:
lemma_word=wordnet_lemma.lemmatize(e)
print('{} -> {}'.format(e,lemma_word))
Output –
wait -> wait waiting -> waiting waited -> waited waits -> wait
. . .