Introduction
How interesting when Youtube, Amazon, Facebook, Spotify, or Netflix give us different suggestions or advertisements according to our likes and dislikes. Well in a more specific way, it gives us recommendations that are relevant to our past choices or are liked by other users with similar tastes.
There are different types of recommendation system, some of are listed below:
- Content-Based Recommendation System
- Collaborative Based Recommendation System
Content-Based Recommendation System
This type of recommendation system aims to suggest items(food, movies, songs, anime, etc.) that are relevant to the user’s choice of interest. It’s more like a user-content-based approach where it calculates similarities between different products. Before we start to calculate similarities we need to convert our data into matrix form which consists of feature vectors.
There are different methods to calculate these similarities.
- Cosine similarities
- Euclidean Distance
- K- Nearest Neighbor(KNN)
1. Cosine Similarities
Cosine similarity is the same as trigonometric function as we have learned in our school days. In the machine learning field, it is generally used to find the distance between two or more vectors.
This method computes the cosine angle between two feature vectors. Formula:
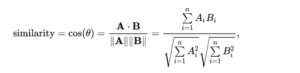
import pandas as pd
import numpy as np
import tensorflow as tf
df = pd.read_csv('dataset.csv')
df.head()

Now we do some preprocessing on our dataset
scaler = MinMaxScaler() df['price'] = scaler.fit_transform(df[['price']]) scaler = MinMaxScaler() df['price'] = scaler.fit_transform(df[['price']]) df.head()

Recommendation: Cosine Similarity
## cosine similarity
def recommend_w_cosine(row_number=None,data=None,n=10):
# now we are comparing our feature vector to matrix
if row_number:
df['similarity'] = cosine_similarity([np.array(df.iloc[row_number,:-1])],Y=df.iloc[:,:-1]).reshape(-1,1)
if data:
df['similarity'] = cosine_similarity(X=data,Y=df.iloc[:,:-1]).reshape(-1,1)
# top 10 similar property
indices2 = df['similarity'].nlargest(n + 1).index
return df.iloc[indices2.values]
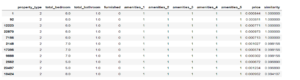
recommend_w_cosine(row_number=1)
Cosine similarity is used in different areas such as Natural Language Processing. It is generally used to find the distance between two or more vectors. You can refer to Cosine Similarity – Text Similarity Metric for more details about Cosine Similarity.
2. Euclidean Distance
This method computes the euclidean distance between two feature vectors. Euclidean Distance is meant to find the minimum distance between two vectors. Calculation of Euclidean distance is the same as we have learned in our school days. It is widely used in Natural Processing Language tasks.
Formula:

Recommend: Euclidean Distance
Here we are using the same dataset as we have used in cosine similarity.
def recommend_w_euclidian(row_number=None,data=None,n=10): # now we are comparing our feature vector to metrcis if row_number: df['similarity'] = euclidean_distances([np.array(df.iloc[row_number,:-1])],Y=df.iloc[:,:-1]).reshape(-1,1) if data: df['similarity'] = euclidean_distances(X=data,Y=df.iloc[:,:-1]).reshape(-1,1) # top 10 similar property indices2 = df['similarity'].nsmallest(n + 1).index return df.iloc[indices2.values]
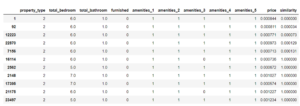
recommend_w_euclidian(1)
3. K- Nearest Neighbour(KNN) Method
Nearest Neighbour is a machine learning algorithm that is used to find the k nearest neighbor. The same concept we are using in the recommendation system to find similar items.
Nearest Neighbour will find k neighbor surrounding to our feature vector with minimum distance.
Recommend: KNN
model_knn = NearestNeighbors(algorithm='ball_tree') model_knn.fit(df)
def recommend_knn(row_number=None,data=None,n=10,model=model_knn): distances, indices = model.kneighbors(df.iloc[row_number,:].values.reshape(1, -1), n_neighbors = 11) return df.iloc[np.squeeze(indices),:-1]
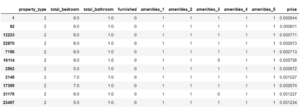
recommend_knn(1)
You can refer to K-Nearest Neighbors (KNN) for a more deep understanding of k-nearest neighbor.