Word Embeddings are basically a type of word representation that allows words with similar meaning to have similar representation where each word is expressed in vector form. Conceptually, Word Embedding involves a mathematical embedding which transforms sparse vector representations of words into a dense, continuous vector space.
Word Embeddings is one of the key breakthroughs of deep learning for solving Natural language Processing problems. In natural language, a word might have multiple meanings, for example, the word “crane” has two meaning such as a crane can be a bird or a large machine used for moving heavy objects. Word Embedding able to identifies the similarity between word based on their context.
The Word Embedding has a pre-defined fixed size vocabulary. There are several existing models are available for Word Embedding representation.
- Word2Vec (Google)
- Glove (Stanford)
- FastText (Facebook)
. . .
Word2Vec
Word2Vec model used to produce word Embeddings. It assigns each unique word to a corresponding vector in vector space representation. Word2Vec was published in 2013 by a team of researchers led by Tomas Mikolov at Google.
Word2Vec model trained on Google News of 100 billion words. There are two different learning model architectures used as part of the Word2Vec to learn the Word Embedding. These two learning models are:
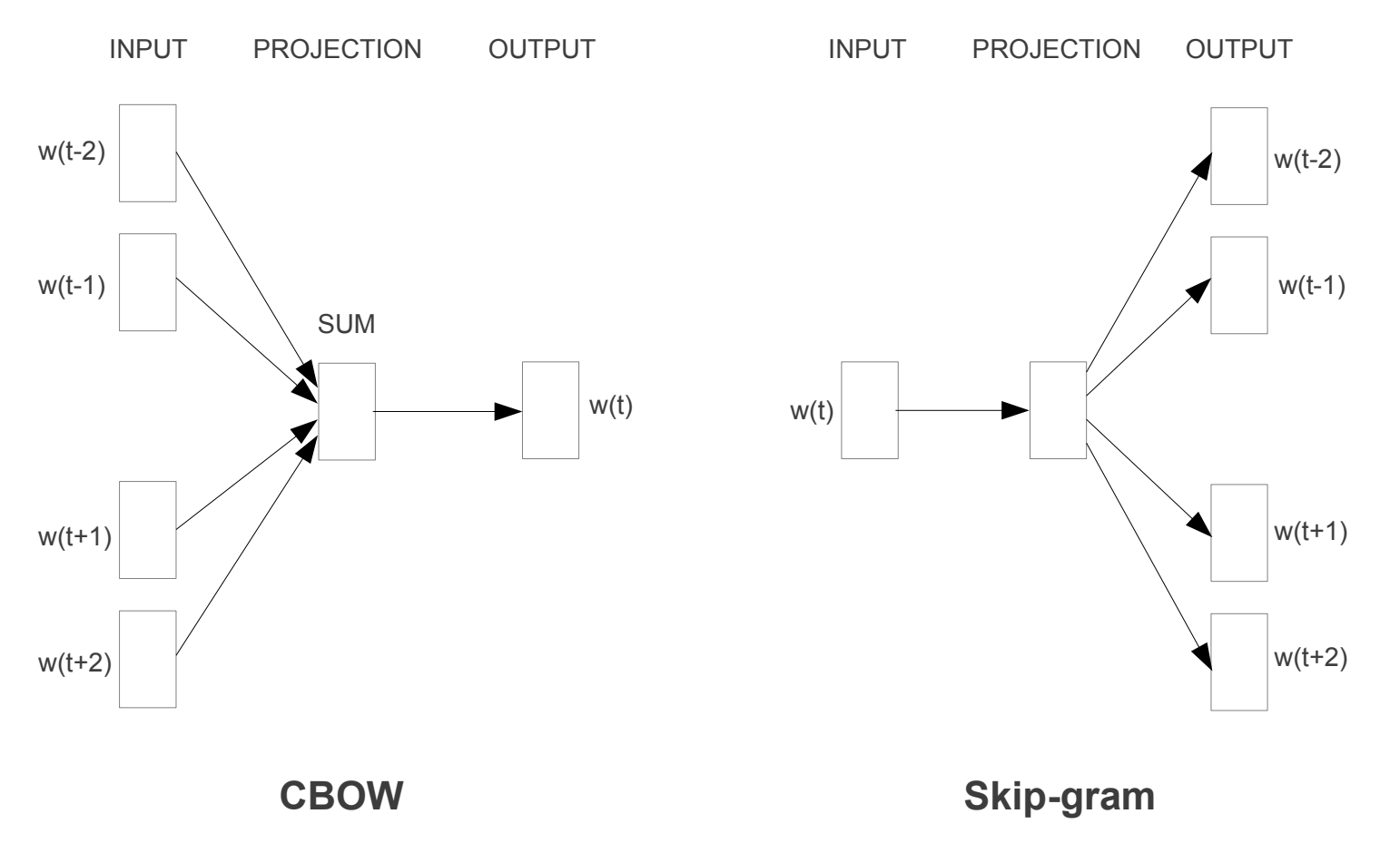
- Continuous Bag-of-Words, or CBOW model.
-
- In CBOW model architecture, the model predicts the current word from a window or surrounding context words.
-
- Continuous Skip-Gram Model.
-
- In continuous Skip-Gram model architecture, the model uses the current word to predict the surrounding window of context word.
-
. . .
GloVe
GloVe (Global Vectors for Word Representation) model is an extension to the Word2vec method for efficiently learning word vectors. The GloVe model created by Pennington at Stanford.
The GloVe is an unsupervised learning algorithm for obtaining vector representations for words. It maps the word into meaningful space where the distance between words is related to semantic similarity. The distance measure used Cosine similarity and Euclidean distance method. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
The GloVe provides various pre-trained word vectors with 50, 100, 200 and 300 dimensions vectors.
. . .
fastText
fastText is a library for efficient learning of word representations and sentence classification. It is written in C++. fastText is created by Facebook’s AI Research Lab. It allows to create a supervised and unsupervised learning algorithm for obtaining vector representations for words.
fastText provides pre-trained word vectors for 157 languages, trained on Common Crawl and Wikipedia. These models were trained using CBOW with position-weights, in dimension 300, with character n-grams of length 5, a window of size 5 and 10 negatives.
fastText also provides pre-trained word vectors for 294 languages, trained on Wikipedia. These vectors in dimension 300 were obtained using the skip-gram model.
. . .