Training a deep neural network that works best on train data as well as test data is one of the challenging task in Machine Learning.
The trained model’s performance can be measured by applying it on the test(unseen) data for prediction. The accuracy is measured by observing the predicted target value and the actual target value.
The trained model can be underfitted or overfitted due to many factors. However, to achieve a good result we need to find the optimal solution that is bestfit.
Underfit Model – The model unable to learn the relationship between the input features and target output variable. It works badly on training data and also performs worst on a test dataset.
Overfit Model – The model has learned the relationship between training dataset’s input features and target output variable very well. It performs best on train dataset but works poor on test data.
Bestfit Model – The model outperforms on both training dataset as well as test dataset.
The under fitted model can be improved by training the model by a longer period of time. But, to deal with an overfitted model is challenging. This tutorial has explained the problem of overfitting and the possible solutions to overcome it.
Why Overfitting?
While training the neural network, the model learns the weight parameters that map the pattern between inputs to outputs. A model with larger weights coefficient becomes model unstable that tends to overfit the training dataset.
Informal way, we can say that the overfitted model memorized the learning patterns between input features and output for the training dataset. Hence, it works best for train dataset but works poor on test unseen dataset.
The solution to this problem is to force the network to keep the weight parameters small and prepare the model more generalized. This can be achieved by regularization techniques.
There are several regularization methods are used to avoid the overfitting. The regularization techniques make smaller changes to the learning algorithm and prepare model more generalized that even work best on test data.
Generally, the concept of the regularization approach is to penalize the larger weight parameter.
- L2 Regularization
- L1 Regularization
- Dropout
- Early stopping
You will discover all these regularization techniques briefly in this tutorial.
L2 Regularization
L2 regularization is also known as weight decay because it forces the weight parameters to decay. L2 Regularization adds the regularization term to the loss function. The regularization term is the squared magnitude of the weight parameter (L2 norm) as a penalty term.
The new cost function along with L2 regularization is:

Here, λ is the regularization parameter that you need to tune. The value of λ is in the range between 0.0 and 1.0. This hyperparameter controls the regularization term.
If λ is too large – the training model underestimate the weight parameters and model will underfit the training dataset
If λ is too small – there is very less effect of regularization term that allows the model to overfit.
To find the perfect choice of regularization parameter λ is a challenging task.
Keras deep learning library provides weight regularization API that will be used to add regularization at each layer.
from keras import regularizers
model.add(Dense(64, input_dim=64, W_regularizer=regularizers.l2(0.01)))
L1 Regularization
L1 regularization is same as L2 regularization but the only key difference is that L1 regularization adds the absolute value of weight parameter (L1 norm) to the cost function as penalty term or regularization term.
The new cost function along with L1 regularization is:

from keras import regularizers
model.add(Dense(64, input_dim=64, W_regularizer=regularizers.l1(0.01)))
Generally, L2 regularization most often used than L1 regularization.
Dropout
Dropout is the regularization technique that randomly ignored some neurons of a layer during training. Dropout regularization can be implemented on the input layer and the hidden layers of the neural network. But, you are not allowed to use it in the output layer.
Dropout regularization set the probability of eliminating a neuron in the neural network. The model will remove that number of neurons and also remove the outgoing link of all those neurons which makes the neural network smaller.
The smaller size neural network sometimes helps to prevent the overfitting. The effect of the specific weight neuron become less sensitive to the model which make the model to generalized and less likely to overfit the training data.
For example, if the specified dropout probability is 0.5 at a particular layer means that the layer randomly eliminates 50% of the neurons and retain the remaining 50% neuron for training.
The dropout probability is another hyperparameter which also needs to be tuned.
| Neural Network | After Applying Dropout |
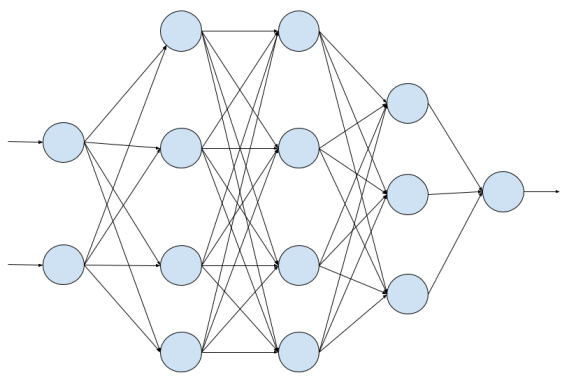 |
 |
Keras deep learning library provides the Dropout core layer. you just need to pass the dropout rate argument to the function.
from keras.layers import Dense, Dropout model.add(Dense(32)) model.add(Dropout(0.5)) model.add(Dense(16))
Note: Dropout regularization doesn’t use while making a prediction on test data.
Early Stopping
Early stopping is another regularization method which helps the neural network to prevent overfitting to the training data. Many cases the neural network overfit when we train the model longer period of the time.
In machine learning, it is one of the biggest question how long we should train the model? Too little training leads the model to underfit and unable to learn the relationship between input features and output. Too much training leads the model to overfit the training dataset that works best for training data but work worst on the test dataset.
The number of model training epoch is another hyperparameter that we need to tune. The best value of the number of training epoch often helps to improve the performance of the neural network.
Early Stopping helps the model to prevent overfitting by monitoring the model performance on the test dataset. The model will stop training when the test performance has stopped improving.
Keras Callback API provides the implementation of the Early Stopping. Early stopping needs validation dataset to observe the model’s performance during the training.
There are two ways to specify the validation data to the Keras’ fit() function using validation_data and validation_split argument. At the end of each training epoch, the model is evaluated on the validation dataset.
from keras.callbacks import EarlyStopping ES = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=5) model.fit(trainX, trainy, validation_data=(valX, valy), epochs=20,callbacks=[ES])
During the training, the model monitors the validation loss metric by evaluating the performance of specified validation data. It will stop training when the validation loss has stopped improving for 5 epoch.
The mode argument in EarlyStopping callbacks –
- min : training will stop when the defining metric has stopped decreasing.
- max: training will stop when the defining metric has stopped increasing.
- auto: automatically inferred from the name of the monitored quantity.
. . .
I read several blogs about machine learning, data science. But this work is very appreciable.
Thanks, Sumit